“The bad news is time flies. The good news is you’re the pilot.” — Michael Altshuler

Why?
Unraveling Skewness and Optimizing Performance
Spark’s repartition() function is a critical tool in data engineering for managing data distribution across partitions. Data in spark applications can become skewed, leading to uneven distribution across partitions, and posing significant challenges to pipeline performance. This can occur post operations like joins or aggregations.
When data becomes skewed, the repartition() function comes into play. It can redistribute this skewed data across partitions without necessarily increasing the number of partitions, thereby improving memory optimization. This is particularly useful when avoiding out-of-memory errors during data processing. By evenly spreading the data, the cluster can better utilize its resources, and the pipeline continues running smoothly.
However, the benefits of repartition() extend beyond skew-handling. It can also be used to:
- Increase the number of partitions when an out-of-memory error occurs during a pipeline run. By adding a repartition stage before the memory-intensive section, you can distribute the data across more partitions, mitigating memory constraints.
- Change the number of partitions when writing data to file systems. Spark creates one output file for each partition. Repartitioning allows you to control this number, which can be beneficial for file management and downstream processing.
- Improve the performance of downstream analytic queries. By partitioning data by specific fields, records with the same value are stored in the same partition. This organization enables faster data retrieval and aggregation during query execution.
The choice of when and how much to repartition is crucial. It involves considering the size of the dataset, the configuration of the cluster, and the memory available. Properly utilizing repartitioning can lead to significant efficiency gains, reduce the risk of pipeline failures, and facilitate faster data analytics.
In summary, Spark’s repartition() function is a versatile tool for data engineers to manage data distribution, optimize performance, and ensure reliable and efficient data processing pipelines.
What is Repartitioning?
Spark repartitioning is a process of redistributing data across different partitions in RDDs or DataFrames to control data distribution and improve performance. It can be done in two ways:
- Coalesce: Reduces the number of partitions by merging existing ones. It is efficient when data size reduces.
- Repartition: Increases or decreases the number of partitions, shuffling data across the network. It is used when data size increases to enhance parallelism.
The False Idea
A wrong image
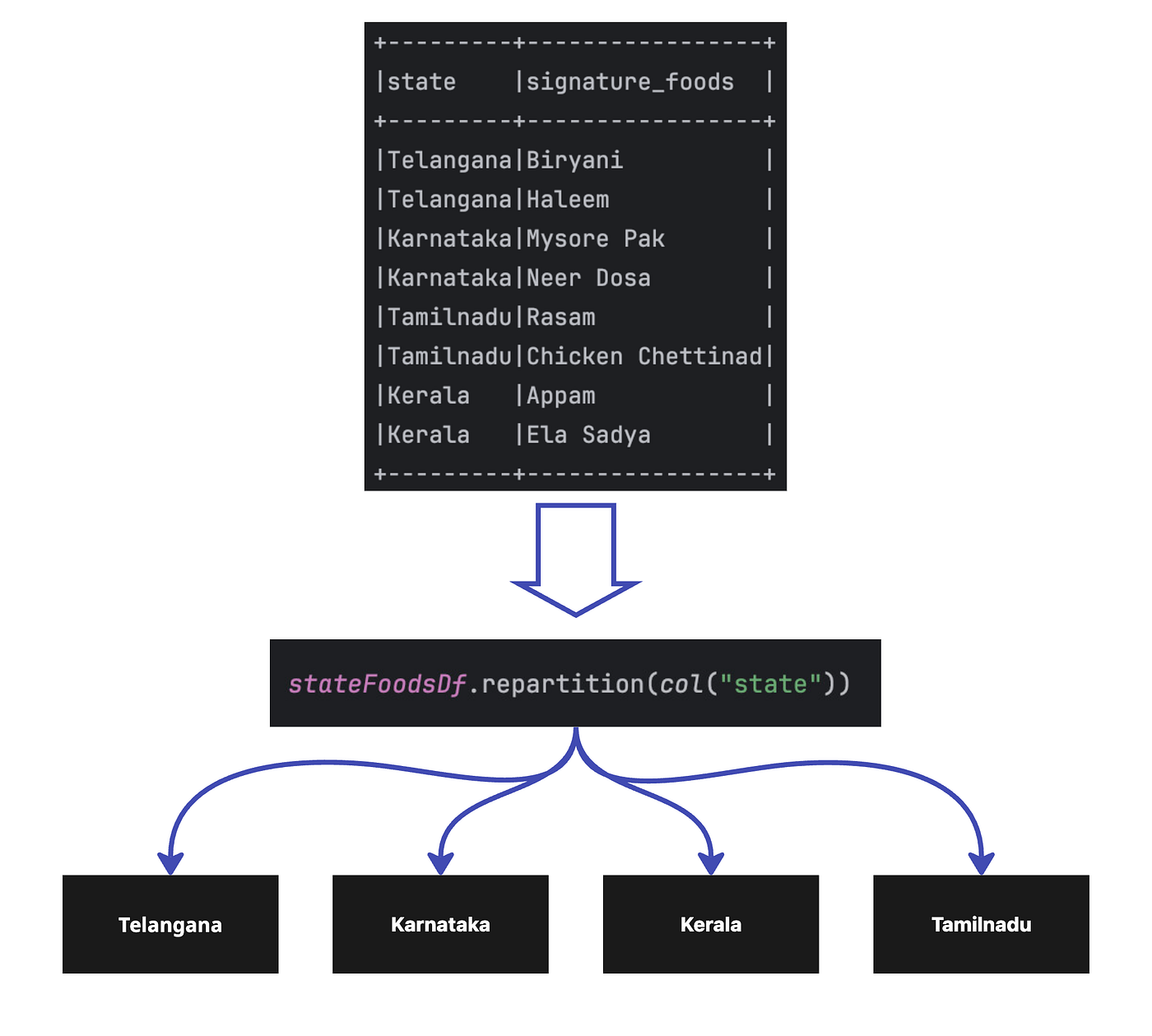
Many assumptions about how repartition() works in Spark are off-base. The misconception is df.repartition(columnName)automatically distributes data based on the values in columnName. It doesn’t! Let’s break down this myth and uncover the truth about how data partitioning actually works. Stay tuned to learn how to optimize your partitioning strategy for improved performance!
Let’s Unlearn
In SQL languages, data partitioning is a technique used to manage large tables by dividing them into smaller, manageable parts based on specific columns, known as partition keys. The goal of partitioning is to improve performance, reduce maintenance overhead, and enable more efficient data handling. A sample Query could be :
SELECT
state,
COUNT(signature_foods) OVER (PARTITION BY state) AS StateWiseCount
FROM stateFoodsDf;Understanding Partitions in Spark DataFrames
In Spark, a distributed parallel computing framework, partitions play a crucial role in data distribution across worker nodes rather than in aggregation. Let’s dispel a common misconception around repartitioning. In reality repartition(columnName) redistributes data for better parallelism and performance, it may not cluster all rows with the same value together. The data is rearranged to optimize efficiency across the cluster, not necessarily for an immediate grouping operation.
Let’s see an example
val covidDf : DataFrame = spark
.read
.option("header", "true")
.csv("data/covid_data.csv")
val repartitionedDf = covidDf
.repartition(col("State/UT"))
.withColumn("partitionId", spark_partition_id())
repartitionedDf.show(false)
repartitionedDf.groupBy("partitionId")
.agg(countDistinct("State/UT").alias("DistinctStateCount"))
.filter("DistinctStateCount > 1")
// Check any partition if that has more than one distinct State/UT
.show(100)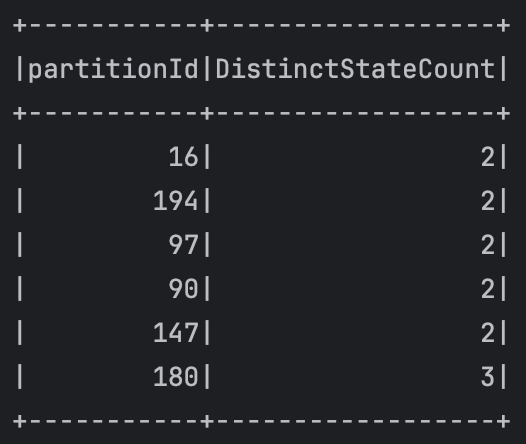
Application
While we understand how spark repartitions in real life it is much important for us while applying it. In case of repartition we must realize this and design our pipeline in efficient manner.
For any type of help regarding career counselling, resume building, discussing designs or know more about latest data engineering trends and technologies reach out to me at anigos.
P.S : I don’t charge money
