
Datalake from bird’s eye
Data lakes are large and unified storage layer that stores all type of data, structured or unstructured, at any scale. It simplifies data management by centralising data and enabling all applications throughout an organization to interact on a shared data repository for all processing, analytics and reporting, significantly improving upon traditional architectures that rely on numerous isolated and siloed systems.
The term “Datalake” was first coined with the Hadoop Distributed File System (HDFS). However, organizations utilize all type of popular public cloud object storage systems such as Amazon S3 or Microsoft Azure Data Lake Storage (ADLS) as datalake store. These cloud data lakes provide organizations with additional benefits such as better managment and provisioning other big data services to simplify data management everywhere to all applications as required.

To better organize data within the massive lakes, organizations use metadata catalogs, which establishes the tables within data lake. With the help of catalogs, all applications share a common repository of data objects, which is helpful for processing and producing consistent results.
Catalogs comprises of the followings :
- Definition of the datasets present in the data lake
- Physical locations of those datasets within the data lake
- Different states of the datasets
The two most popular catalog services are Hive Metastore (HMS) and AWS Glue Data Catalog. Be it Hive or Glue, they contain the schema, table structure and data location for datasets which provides a similar structure as relational databases in that they are deployed on top of file storage and shared across multiple applications. This ensures consistency between different applications and simplifies data management.
Where did the titanic sink?
The catalog service provides metadata tracking, management but it was not enough as they do not track data changes or schema evolution between applications in a consistent transactional or atomic manner.
Consider a scenario where you have Retail application which is backed by an OLTP system and you need to update your inventory when a customer orders something and it gets delivered. Think of another use case where you are maintaining a big data warehouse of supply chain data and you want to merge data of two logistics partner. In conventional datalake system you can not do that with ease. You need a very efficient coordinator system in place which can do that job for you. Without automatic coordination of data changes to your applications in the data lake, organizations need to create complicated pipelines or staging areas which can be brittle and difficult to manage manually. Which is a nightmare.
Here comes the saviour — Iceberg
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to compute engines including Spark, Trino, PrestoDB, Flink and Hive using a high-performance table format that works just like a SQL table.
This new table format that solves the challenges and is rapidly becoming an industry standard for managing data in data lakes. Iceberg introduces new capabilities that enable multiple applications to work together on the same data in a transactionally consistent manner and defines additional information on the state of datasets as they evolve and change over time.
The Iceberg table format has similar capabilities and functionality as SQL tables in traditional databases but in a fully open and accessible manner such that multiple engines (Dremio, Spark, etc.) can operate on the same dataset. Iceberg provides several out of the box features as following:
- ACID Compliance just like an OLTP database.
- Full schema evolution to track changes to a table over time.
- Time travel to query historical data and verify changes between updates.
- Partition layout and evolution enabling updates to partition schemes as queries and data volumes change without relying on hidden partitions or physical directories.
- Rollback to older versions to rectify issues and go back to the a desired prior state.
- Advanced planning, filtering, pruning capabilities for high performance on large data volumes.
- O(1) listing of data files so that it efficiently prune files not just the partition or columns like what Hive/Spark does with O(N) listings.
How iceberg does these wonders?
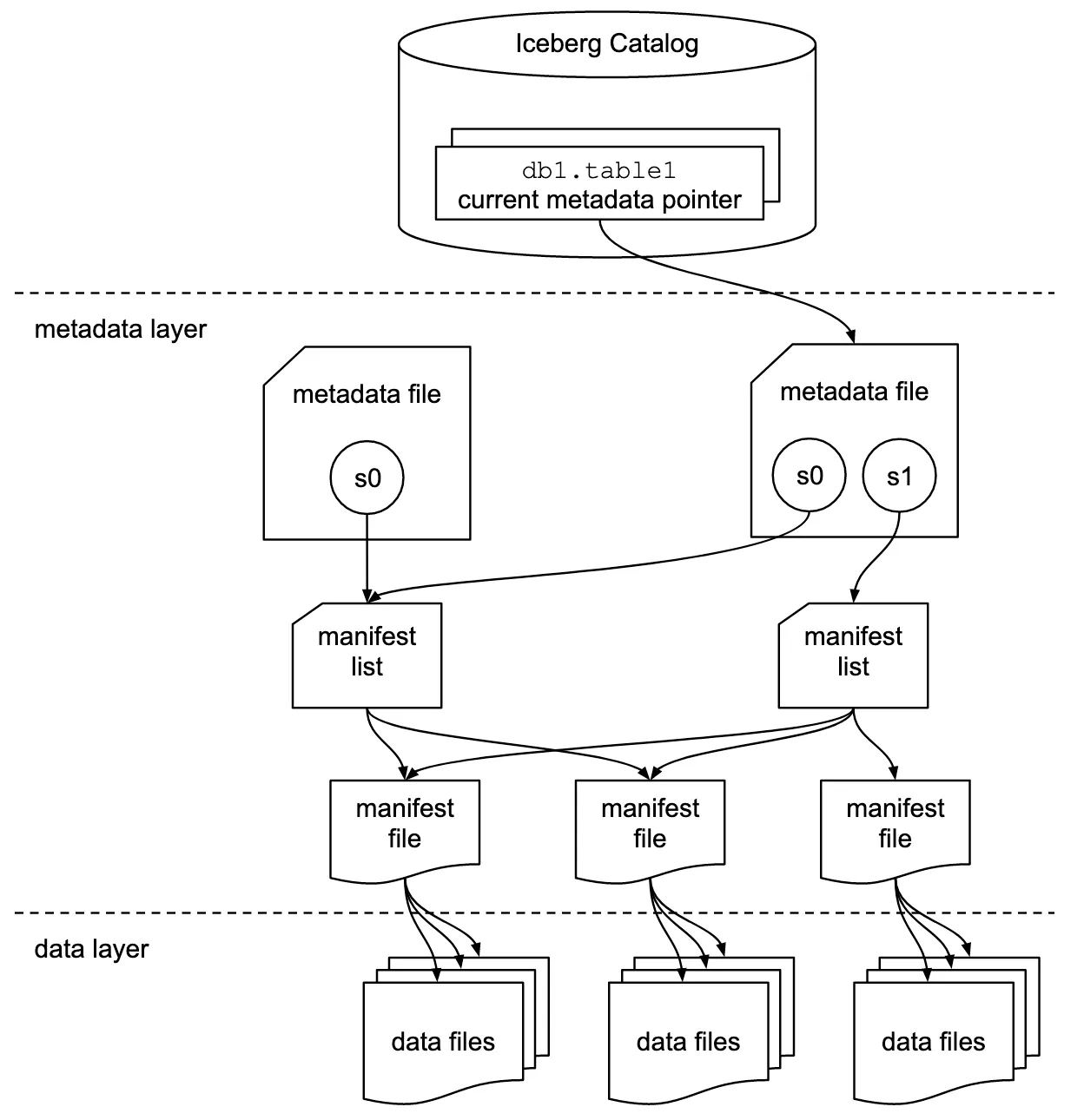
This table format tracks individual data files in a table instead of directories. This allows writers to create data files in-place and only adds files to the table in an explicit commit.
Table state is maintained in metadata files. All changes to table state create a new metadata file and replace the old metadata with an atomic swap. The table metadata file tracks the table schema, partitioning config, custom properties, and snapshots of the table contents. A snapshot represents the state of a table at some time and is used to access the complete set of data files in the table.
Data files in snapshots are tracked by one or more manifest files that contain a row for each data file in the table, the file’s partition data, and its metrics. The data in a snapshot is the union of all files in its manifests. Manifest files are reused across snapshots to avoid rewriting metadata that is slow-changing. Manifests can track data files with any subset of a table and are not associated with partitions.
The manifests that make up a snapshot are stored in a manifest list file. Each manifest list stores metadata about manifests, including partition stats and data file counts. These stats are used to avoid reading manifests that are not required for an operation.This table format tracks individual data files in a table instead of directories. This allows writers to create data files in-place and only adds files to the table in an explicit commit.
Benefits of Using Iceberg
An atomic swap of one table metadata file for another provides the basis for serializable isolation. Readers use the snapshot that was current when they load the table metadata and are not affected by changes until they refresh and pick up a new metadata location.
Writers create table metadata files optimistically, assuming that the current version will not be changed before the writer’s commit. Once a writer has created an update, it commits by swapping the table’s metadata file pointer from the base version to the new version.
If the snapshot on which an update is based is no longer current, the writer must retry the update based on the new current version. Some operations support retry by re-applying metadata changes and committing, under well-defined conditions. For example, a change that rewrites files can be applied to a new table snapshot if all of the rewritten files are still in the table.
The conditions required by a write to successfully commit determines the isolation level. Writers can select what to validate and can make different isolation guarantees.
What are the other table formats and how Iceberg is beating them?
HUDI, Hive ACID Tables, Databricks Delta are alternatives to Iceberg but they are engine specific like HUDI and Delta can be operated using Spark and Hive ACID Table can be operated using Hive. On the other hand Iceberg is not engine specific. Also it has no constraint of underlying file format, it supports ORC and Parquet both with any compression unlike Hive ACID with ORC and Delta with Parquet. Multiple successful production deployments are already done with Iceberg with tens of petabytes and millions of partitions. It is 100% open source and independently governed.
For any questions please reach out to my linked in profile : anigos
Content help : https://www.dremio.com/data-lake/apache-iceberg/, https://iceberg.apache.org/#
To know more : https://iceberg.apache.org/#
